
 首页
首页 中心概况
中心概况 平台建设
平台建设 人才队伍
人才队伍 科研成果
科研成果 人才培养
人才培养 产业发展
产业发展 招贤纳士
招贤纳士 全国颠覆性技术创新
全国颠覆性技术创新










人才培养|京津冀国家技术创新中心-香港大学2024级创新创业博士生赵俊杰全球牙科评测基准GlobalDentBench正式发布
本文转载自“自由动脉”微信公众号
编者按

GlobalDentBench是一个面向牙科临床推理与安全性的评测基准,由京津冀国家技术创新中心、香港大学牙医学院、香港中文大学(深圳)、南方医科大学深圳口腔医院(坪山)、北京大学、梅奥诊所、慕尼黑大学医院及深圳自由动脉科技有限公司共同推进。其数据来源覆盖六大洲的 88 个国家和地区,包含 14 个口腔医学专科方向和 8,978 道经专家验证的问题。不同于主要依赖选择题的传统评测,GlobalDentBench 进一步纳入了简答题和基于真实临床病例报告构建的病例题,并按照知识回忆、常规推理和个体化推理三个层级逐步提升难度。6 位资深牙医深度参与了基准构建与评测校准。它希望回答的,不只是“大模型能否通过牙医考试”,更是“当模型真正面对复杂病例和潜在临床风险时,是否仍然可靠”。
大模型在医学考试中屡创高分,然而当考场变成诊室,当面对一位捂着腮帮子的真实患者时,它真的能胜任“牙医”的角色吗?
真实的临床博弈,从来不是非黑即白的单项选择。 一颗患牙交织着感染、咬合等复杂病理,医生需在“查病因、定顺序、防并发”中寻找最优解。脱离具体病情的AI建议,极易导致误诊,甚至造成不可逆的损伤。遗憾的是,现有评测多停留在衡量AI理论水平的“应试”舒适区,难以回答一个更重要的问题:
当问题从“选出正确答案”变成“为一位具体患者制定治疗方案”时,大模型还能可靠吗?
为了打破高分幻觉,填补AI走向真实临床的鸿沟,GlobalDentBench 应运而生。该项目由京津冀国家技术创新中心与香港大学联合培养的2024级创新创业博士生赵俊杰主导研发,全球顶尖力量推进:港中大(深圳)王本友教授团队、港大牙医学院王俊文教授团队、南医大深圳口腔医院(坪山)江山副院长团队、港大牙医学院杨伟发教授团队、北大陈良怡教授团队与深圳自由动脉科技。同时,港大金力坚院长、南医大深圳口腔金作林院长,携手美国梅奥诊所 Nhan Tran 教授、慕尼黑大学 Falk Schwendicke 教授等国际权威倾力加盟,筑牢临床安全壁垒。
作为首个面向牙科临床推理与安全评估的多国评测基准,GlobalDentBench以极致的广度与深度,为 AI 迈向真实临床构建了全新的参考坐标:
-
全球视野:覆盖88个国家和地区,反映真实的全球诊疗差异; -
临床深度:细分14个专科,含8,978道直击临床痛点的高质量考题; -
专家标准:6位资深牙医耗时297小时纯人工交叉检验,严守临床底线。
跳出执业考试的分数执念,GlobalDentBench向整个医学 AI 领域抛出那个严酷却必须面对的终极拷问:
当褪去应试的伪装,直面复杂的真实病例、潜在的临床风险以及严肃的诊疗抉择时,人工智能到底能走多远?
[01 不只考知识,还要考临床推理]
GlobalDentBench 考察模型能否从复杂病例中提取关键线索、完成诊断推理,并给出合理的治疗决策。
为了让评测逐步接近真实牙科诊疗,GlobalDentBench 设置了三类题型:
MCQ:选择题。 来自多个国家和地区的牙医资格考试,主要考察基础知识和标准化判断。
SAQ:简答题。 来自权威牙科教材,要求模型脱离选项提示,独立组织答案。
CBQ:病例题。 来自同行评审的临床病例报告,要求模型结合病史、临床表现和个体化信息,完成诊断推理与治疗决策。
从选择题到简答题,再到病例题,题目逐步从“知识回忆”走向“临床推理”。
与此同时,每道题还会按照推理难度,进一步划分为三个层级:
L1:知识回忆。 主要考察模型是否掌握明确、标准的牙科医学知识。
L2:常规推理。 需要根据典型临床表现,完成常规诊断或治疗逻辑推断。
L3:个体化推理。 需要整合患者特异信息、非标准情况和现实约束,作出更加接近真实临床的判断。
简单来说:
L1 更像“背书”,L2 更像“做题”,而 L3 才更接近“面对一个具体患者”。

图1: GlobalDentBench 总览。基准覆盖全球来源、三类题型、三个推理层级和 14 个牙科专科。
[02 大模型擅长考试,但一旦面对真实病例,就开始“掉链子”。]
我们评测了 12 个前沿大语言模型,包括 Gemini、GPT、Claude、Grok、Doubao、DeepSeek、Kimi、GLM、Qwen、MiniMax 等系列模型。
他们的结果呈现出非常清晰的阶梯式下降:
在选择题上,平均准确率为 81.34%。
到了简答题,平均准确率下降到 64.53%。
到了真实病例驱动的病例题,平均得分进一步下降到 22.34%。
如果按照推理层级来看,趋势同样明显:L1 知识回忆任务平均得分 74.01%,L2 常规推理下降到 55.64%,L3 个体化推理只有 35.71%。这说明,大模型在牙科场景中的主要能力仍然更接近“知识检索与规范表达”。一旦任务需要结合具体患者信息进行个体化推理,所有模型都会遇到共同瓶颈。
换句话说:
大模型很会答题,但还不真正擅长处理真实的临床问题,还不足以应对较为复杂的临床问题。
在总体宏平均分上,Gemini-3.1-Pro-Preview 取得最高分,达到 63.27%。开源模型中,GLM-5 表现最好,达到 56.43%。
但如果进一步考虑推理成本,模型之间的差异就不只是性能高低。Gemini-3-Flash-Preview 以 61.59% 的宏平均分和每 1000 次查询约 3.72 美元 的成本,呈现出较好的成本-性能平衡。Kimi-K2.5 的宏平均分为 55.49%,每 1000 次查询成本约 1.37 美元,在开源模型中也很有竞争力。
换句话说,在牙科知识辅助、教学或研究场景中,“模型是否足够强”之外,还需要问“它在特定任务上是否值得这个成本”。但对于复杂临床决策,即使是表现最好的模型,目前也还远远不能独立使用。
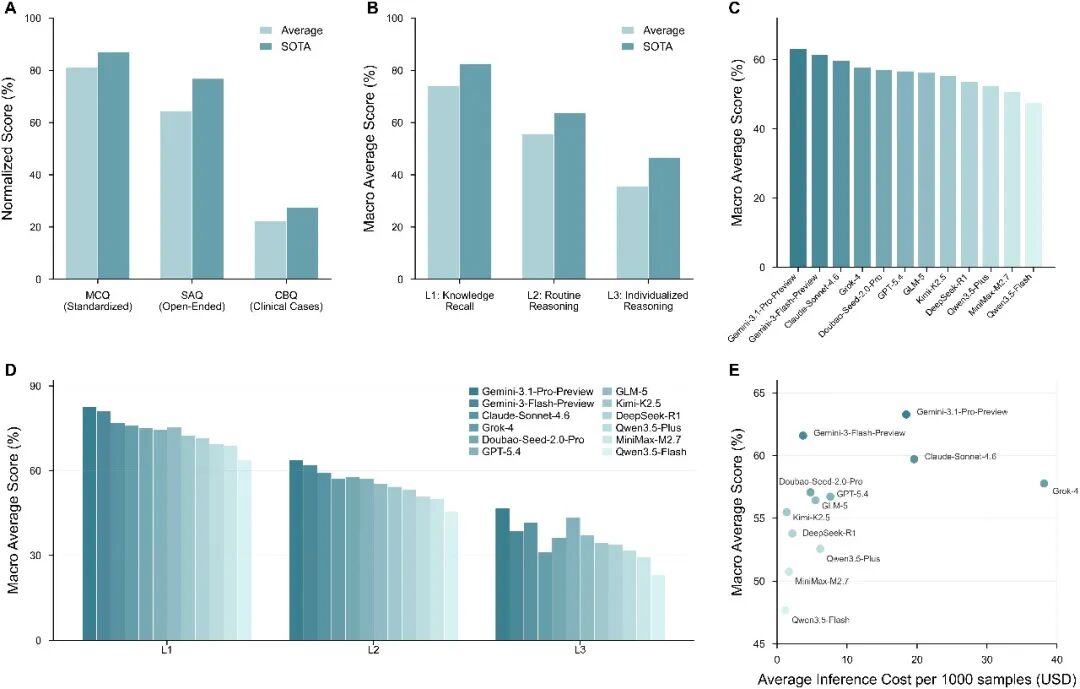
图2:12 个前沿模型在不同题型、不同推理层级下的表现,以及成本-性能关系。
[03 大模型也会“偏科”:不同牙科专科之间,表现差异明显]
GlobalDentBench 的一个重要特点,是将题目映射到 14 个牙科专科。这样我们就能看到,模型的能力并不是在所有牙科领域都表现一致。
总体上,模型在 口腔黏膜病、牙髓与根尖周疾病、口腔颌面影像 等领域表现相对更好;而在 正畸、儿童牙科、传统修复 等领域表现更弱。
一个可能的原因是,不同专科对临床推理的要求并不相同。口腔黏膜病、牙髓与根尖周疾病等领域中的部分知识,更容易通过相对标准化的术语、疾病模式和诊疗逻辑进行表达。而正畸、儿童牙科和传统修复等任务,往往更加依赖发育阶段、长期治疗规划、行为管理、程序设计和患者个体化约束。
即使这些信息已经通过文字呈现,模型仍然需要完成更加复杂的整合与权衡。
因此,一个总体分数看起来不错的模型,并不一定在所有牙科医学场景中都同样可靠。
平均分可能掩盖专科差异。大模型在介入真实牙科临床场景之前,必须接受更加细粒度的专科验证。
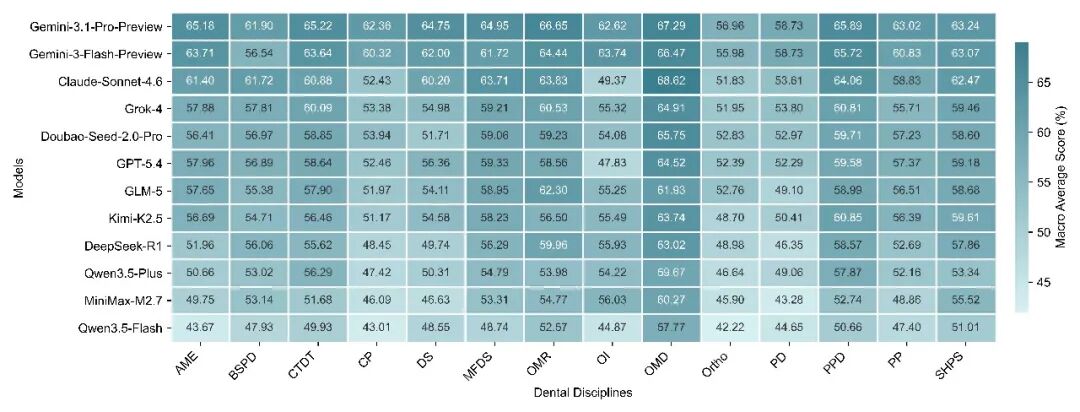
图3:不同模型在 14 个牙科专科上的宏平均得分。模型在各专科上的表现存在系统性差异。
[04 比答错更值得警惕的,是给出危险建议]
对于医疗 AI 来说,错误并不只是一个分数。
有些错误只是表述不够完整。有些错误可能导致额外检查、治疗返工或可避免的并发症。还有一些错误,则可能造成牙齿丧失、永久功能损害,甚至延误严重疾病的处理。
因此,在病例题中,我们进一步分析了模型回答的临床安全风险,每条回答会被划分为三个等级:
S0:临床安全或低风险回答。
S1:可能造成可逆患者伤害的危险回答。
S2:可能造成不可逆或危及生命伤害的危险回答。
例如,错误的治疗顺序、可避免的并发症或需要额外返工的建议,可能被归入 S1。而可能导致牙齿丧失、永久感觉神经损伤、药物相关性颌骨坏死,或者延误恶性肿瘤和严重感染处理的建议,则可能被归入 S2。
在 12 个模型对 1,590 道病例题生成的 19,080 条回答中,整体不安全率达到 31.01%。其中,26.50% 属于 S1,4.51% 属于 S2。
换句话说:
在病例题中,接近三分之一的大模型回答存在潜在临床风险。
更值得注意的是,这些风险并不是均匀分布的。
不同模型之间的整体不安全率差异很大,从 15.97% 到 45.85% 不等。
不同专科之间,也呈现出不同的风险结构。例如,正畸的整体不安全率最高,达到 44.30%。
而更严重的 S2 风险,则更多集中在以下临床敏感领域:
系统健康、药理与安全:14.15%
麻醉与医疗急症:8.93%
儿童牙科:6.33%
这意味着,仅仅比较平均分是不够的。一个模型总体得分较高,仍然可能在少数高风险场景中给出严重错误的建议。一个模型整体不安全率较低,也不代表它一定能够避免偶发但严重的 S2 错误。
这意味着,单看正确率平均分可能会掩盖真正的临床风险。一个模型总体看起来不错,仍然可能在少数高风险场景中给出严重危险建议。
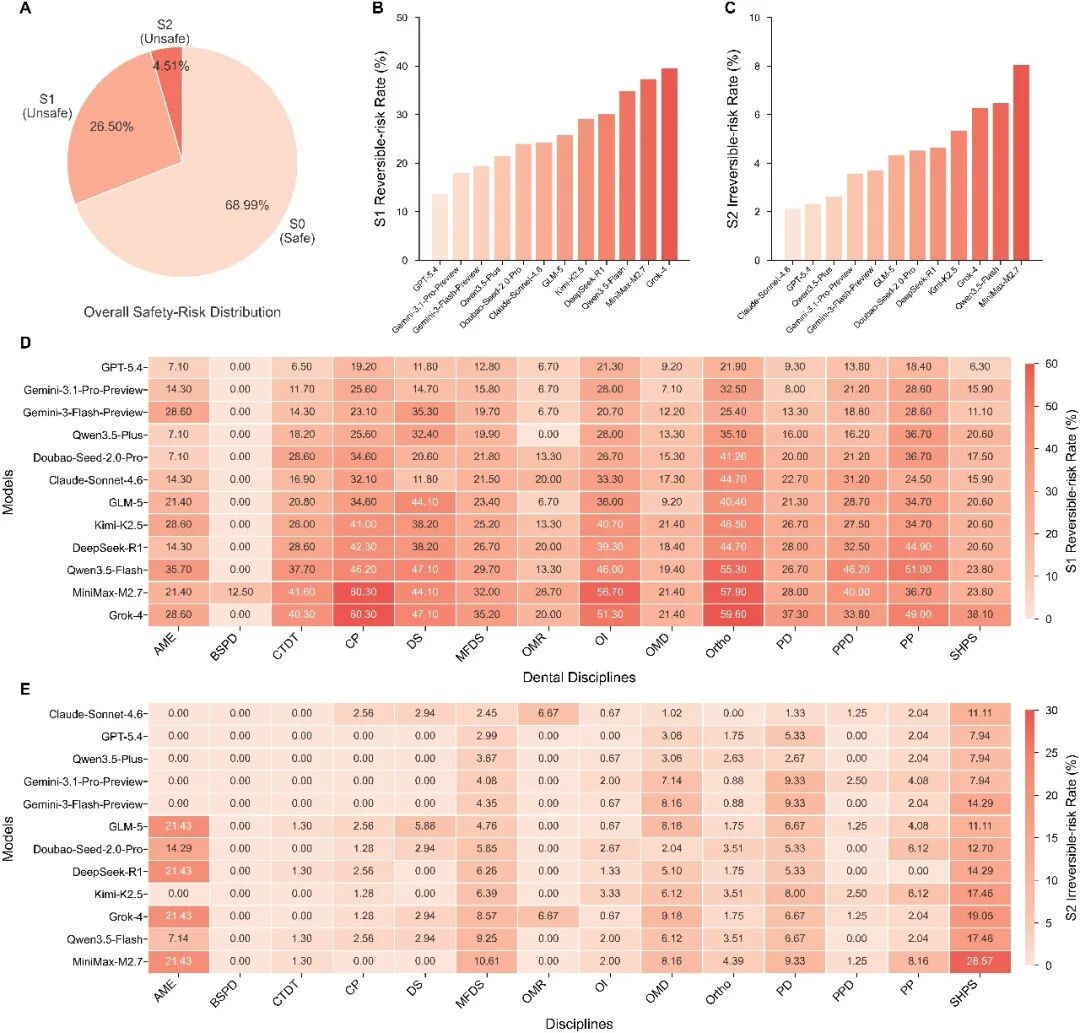
图4:病例题回答的安全风险分析。GlobalDentBench 不只评估答得对不对,也评估潜在临床伤害。
[05 Benchmark是如何构建的?]
为了让评测同时具备规模、临床相关性和可信度,我们从三类来源构建题目:
|
|
|
|
|
|
|
|
|
|
|
|
构建过程中,我们使用自动化 agent pipeline 将异构文档统一转成标准格式,再根据题型抽取或生成样本,并进行专科标签与推理层级标注。为了控制质量,流程中加入了自我校正与专家验证。
GlobalDentBench 并不是把 AI 生成的题目简单汇总成数据集。为了让题目真正符合牙科临床逻辑,我们引入了 Dentist-in-the-Loop 框架:6 位持证资深牙医(平均执医6.8年)全程参与数据源认证、分类体系制定、agent pipeline 优化、样本质量审核和自动评分框架校准。
这部分工作从 2026 年 2 月 5 日 持续到 2026 年 3 月 25 日。在 33 个工作日中,每位专家平均每天投入 1.5 小时,累计形成 297 人工时 的专业审核与反馈。专家不是在最后“盖章”,而是在构建流程中不断指出潜在问题,帮助系统修正题目的临床还原度、标签稳定性和临床合理性。
最终,选择题与简答题的专家一致率达到 99.98%;更复杂的病例题中,专家人工病例题总量的 32.89%,临床接受率达到 96.78%。在自动评分环节,经过牙医校准的 judge model 的临床接受率达到了98%。
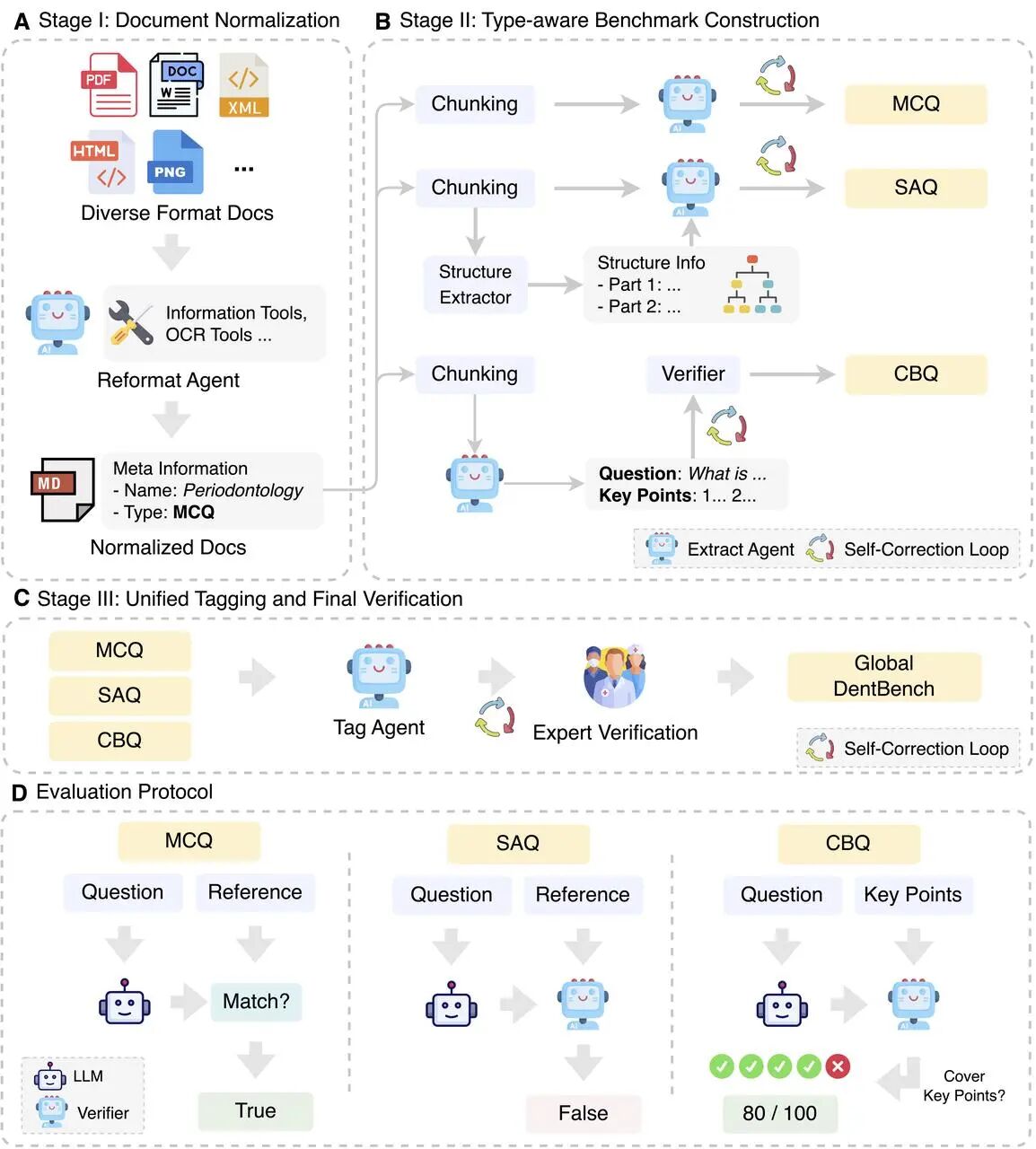
图5:GlobalDentBench 的构建与评测流程。自动化 pipeline 负责文档标准化、题目构建、标签标注与最终验证,开放题由经专家校准的 judge model 进行评分。
[GlobalDentBench想说明什么?]
GlobalDentBench 的核心结论可以概括为一句话:
当前大模型可以成为牙科知识检索、教育和分析的辅助工具,但还不能作为自主牙科临床决策者。
这并不是否定大模型在医疗中的潜力。相反,只有把能力边界讲清楚,才能让模型更稳妥地进入真实工作流。
对于研究者,GlobalDentBench 提供了一个更接近真实牙科临床推理的评测框架。它把题型、推理层级、牙科专科和安全风险放在同一个体系里,让我们不再只比较一个总分。
对于开发者,它提供了一种可迁移的医学 benchmark 构建方法:用自动化 agent pipeline 处理异构来源,用专家校准控制质量,用 key-point scoring 和风险分级评估开放式临床回答。
对于临床和监管场景,它强调了一个重要原则:
在高风险医疗任务中,模型部署前必须经过专科验证、风险评估和专家把关的严格流程。
[ 开放资源 ]
我们已经公开项目代码和无版权限制的开放子集,方便研究者复现、评测和扩展。
论文
https://arxiv.org/abs/2605.24636
Github
https://github.com/FreedomIntelligence/GlobalDentBench
可公开子集GlobalDentBench-OA
https://huggingface.co/datasets/FreedomIntelligence/GlobalDentBench
[ 合作单位]
GlobalDentBench 是一个跨机构、跨学科合作项目,参与团队覆盖口腔医学、人工智能、医学影像、生物医学研究与临床医院等方向。主要参与机构包括:
-
香港大学牙医学院 Faculty of Dentistry, The University of Hong Kong -
香港中文大学(深圳)The Chinese University of Hong Kong, Shenzhen -
南方医科大学深圳口腔医院(坪山)Shenzhen Stomatology Hospital (Pingshan) of Southern Medical University -
北京大学 Peking University
-
北大清华生命科学联合中心 Peking-Tsinghua Center for Life Sciences -
国家生物医学成像中心 National Biomedical Imaging Center -
新基石科学实验室 New Cornerstone Science Laboratory -
梅奥诊所 Mayo Clinic -
德国慕尼黑大学医院 LMU University Hospital -
深圳河套学院 Shenzhen Loop Area Institute -
深圳自由动脉科技有限公司 Freedom AI -
北京协同创新研究院 Beijing Institute of Collaborative Innovation
[总结]
如果用一个更直观的方式总结这篇工作:我们并不是只想知道,大模型能不能通过一场牙科考试。我们更想知道,当它面对的是真实患者、真实风险和真实临床推理时,它还能走多远。
GlobalDentBench 给出的答案是:
大模型已经展现出可观的牙科知识问答能力,但距离安全、可靠地承担临床决策,仍然有很长的路要走。
更值得关注的是,这种局限并不是个别模型的问题。在复杂病例和个体化推理任务中,无论是闭源模型还是开源模型,都表现出了相似的能力瓶颈。
[未来展望]
未来,我们将会继续致力于推进牙科与AI的结合,并着重沿着两个方向推进:
从「测能力」走向「探边界」:推进 GlobalDentBench 2.0
下一阶段,我们将进一步升级 GlobalDentBench:不再追求题目数量的简单扩展,而是更加关注前沿模型的能力边界。
GlobalDentBench 2.0 将重点收录真正能够难住前沿模型的问题,引入更细致的 Rubric 评估开放式医学推理能力,并邀请来自不同国家和地区的专家持续参与审核与校准。
与此同时,我们也期待与更多高校、医院及相关机构开展合作,共同探索口腔医学与人工智能的更多可能。有意向的合作伙伴可通过 ziiyingsheng@gmail.com 与我们联系,进一步探讨合作机会。
从「通用模型」走向「专科优化」:探索专业化口腔医学模型
仅仅依靠规模更大的通用模型,可能仍不足以解决真实口腔临床中的复杂问题。
未来,一个值得探索的方向,是构建更加专业化的口腔医学模型:围绕高质量专科数据进行训练,引入口腔医生持续参与的校准机制,并针对临床推理、治疗规划和安全风险进行专项优化。
它未必会替代通用大模型,但可能成为推动医疗 AI 从「会答题」走向「真正可用」的重要一步。