
 首页
首页 中心概况
中心概况 平台建设
平台建设 人才队伍
人才队伍 科研成果
科研成果 人才培养
人才培养 产业发展
产业发展 招贤纳士
招贤纳士 全国颠覆性技术创新
全国颠覆性技术创新










企业风采|世界第一!深势科技同合作伙伴联合推出DPA4 登顶Matbench Discovery与SPICE-MACE-OFF
本文转载自“深势科技 DP Technology”微信公众号
编者按
大原子模型的竞争,正在从“谁更大”转向“谁更强、更快、更便宜”。
近日,深势科技作为核心贡献者,与北京科学智能研究院、北京大学、北京应用物理与计算数学研究所等合作伙伴紧密协作,依托开放协同的科研合作生态,联合推出面向大原子模型(LAM)时代的新一代模型架构 DPA4。
在材料发现领域国际权威榜单 Matbench Discovery 上,DPA4 以综合性能指标 CPS 位列世界第一,成为最新 SOTA 模型。
更值得关注的是,DPA4 并不是靠堆参数、堆算力登顶。相比此前领先模型 eSEN 需要 300 余 GPU days 的训练成本,DPA4 理论上仅需 一张 RTX 5090 训练约一天,即可达到同等级精度;同时参数量不到 eSEN 的十分之一。
也就是说,过去需要“超级算力预算”才能触达的 SOTA 精度,现在有机会被压缩到一张消费级显卡上完成。DPA4 正在重构大原子模型的“精度-效率”帕累托前沿。
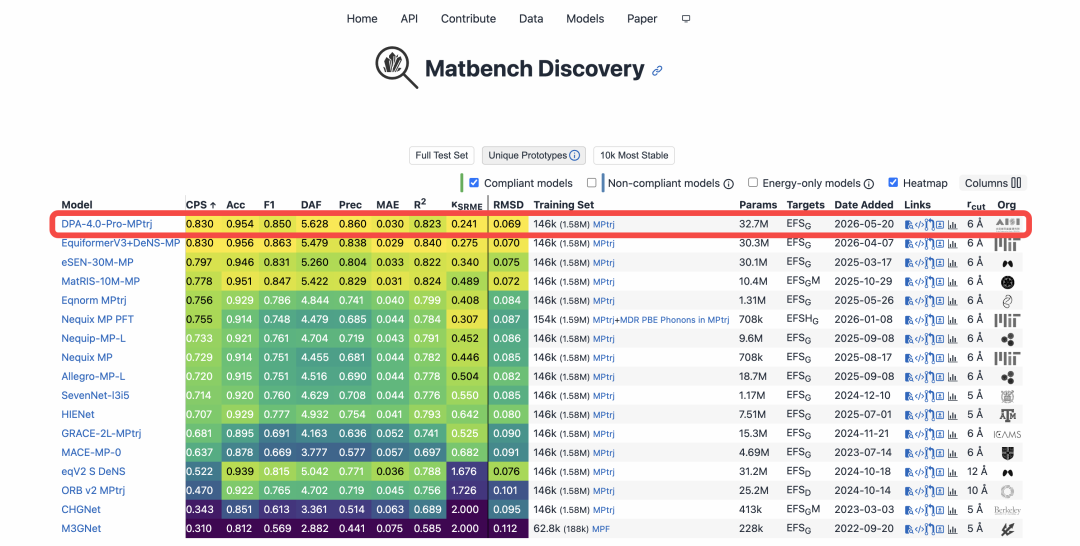
Matbench Discovery 官方截图,数据截至 2026 年 5 月 22 日
DPA4 采用局部坐标系下的 SO(2) 等变线性算子结合注意力机制的设计,在严格满足平移、旋转、排列对称性与能量守恒的前提下,大幅压缩了等变计算的开销,并在世界范围内率先实现机器学习势函数的compile训练,将训练速度提升 2-3 倍。在材料发现领域国际权威榜单 Matbench Discovery 与小分子基准 SPICE-MACE-OFF 上,DPA4 均取得了新的 SOTA 成绩,双双位列世界第一。
尤为突出的是,DPA4 在预测精度与训练成本上同时达到了全新的帕累托前沿:理论上仅需单张 RTX 5090 显卡训练约一天,即可达到 eSEN 此前耗费 300 余 GPU days 才能实现的精度水平,并且参数量不到后者的 1/10;而在相同精度下,其训练效率较上一代 DPA3 进一步提升约 10 倍。
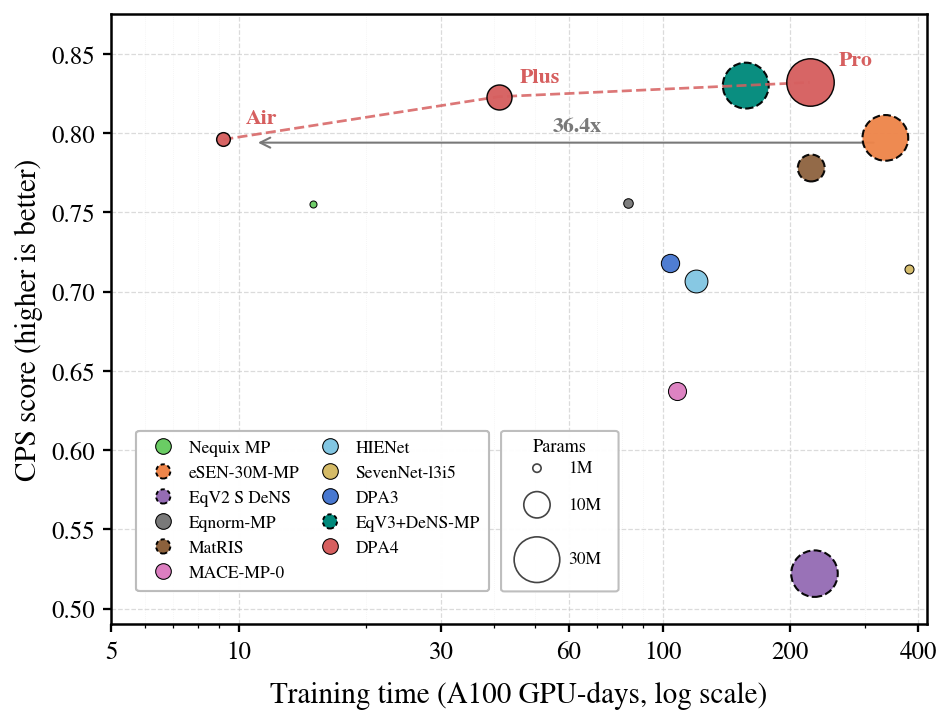
DPA4重构大原子模型“精度-效率”帕累托前沿(含其余Direct Force预训练模型)
目前 DPA4 已面向 Deep Modeling 社区开放尝鲜,论文与正式版本将于后续陆续开源,欢迎广大研究者持续关注并加入文末微信尝鲜群交流。以下为详细的DPA4介绍。
01 DPA4 模型结构:局部坐标系下的SO(2) 等变设计
长期以来,等变模型为了在全局坐标系下保持旋转对称性,必须依赖 Clebsch–Gordan 张量积来耦合不同阶的几何特征,其计算复杂度随角动量阶数 急剧增长(约 ,这正是高精度等变模型计算昂贵的根本原因。
DPA4 的核心思路是:与其在全局坐标系下承担昂贵的张量积,不如把对称性"约化"到更简单的子群上处理。具体而言,对每一条原子间的边,DPA4 都构造一个光滑的局部坐标系,将该边方向对齐到统一的参考轴。在这一局部坐标系中,原本需要在整个 SO(3) 群上处理的旋转等变性,被约化为仅需在绕轴旋转的 SO(2) 子群上处理——而 SO(2) 是阿贝尔群,其等变线性映射具有极为简洁的分块结构。由此,昂贵的 SO(3) 张量积被等价地替换为高效的 SO(2) 等变线性算子,在严格保持完整旋转等变性的同时,将角向计算的开销大幅压缩。
在此基础上,DPA4 进一步引入注意力机制完成邻居信息的聚合:模型能够根据局部几何与化学环境,自适应地"关注"对中心原子最关键的相互作用,从而在紧凑的参数规模下获得强大的表达能力。整个模型严格满足平移、旋转、排列对称性与能量守恒,物理一致性得到完整保证。
除算法层面的设计外,DPA4 在工程实现上同样面向效率优化:
原生 torch.compile 支持:模型从设计之初即对编译友好,可直接借助
torch.compile获得显著的端到端加速,无需额外改写。原生 ZBL 短程势:DPA4 原生集成 ZBL 排斥势,平滑衔接近距离的物理行为,使模型在高压、辐照、缺陷等极端构型下更加稳健可靠。
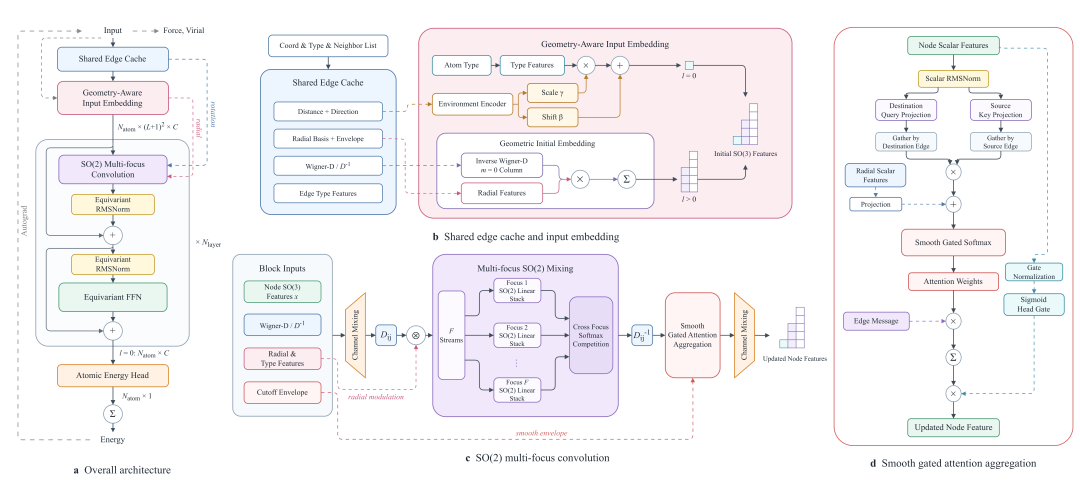
DPA4模型结构
02 Matbench Discovery与 SPICE-MACE-OFF双双登顶
材料发现:Matbench Discovery 世界第一。 Matbench Discovery 由加州大学伯克利分校、剑桥大学等顶尖机构发起,是全球 AI 驱动无机材料发现领域最具影响力的动态基准榜单,被公认为衡量材料科学智能模型性能的国际金标准。它摒弃了简单的静态数据拟合,转而通过前瞻性测试机制,要求模型预测数十万种未知晶体的热力学稳定性,真实还原科研探索的全过程;其评价体系不仅考察能量与力的预测精度,还综合 F1 分数、发现加速因子等多项指标,最终汇聚为综合性能分数 CPS。在汇集了 Meta、微软及全球顶尖高校最强模型的同台竞技中,DPA4 以 CPS 综合性能位列世界第一,成为最新的 SOTA 模型。
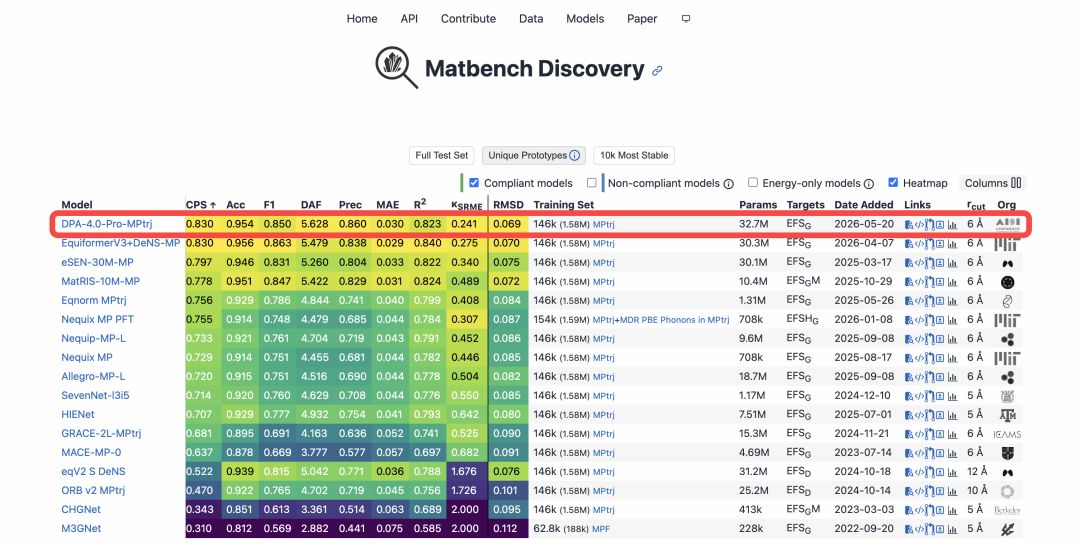
Matbench Discovery官方截图,数据截至2026年5月22日
小分子:SPICE-MACE-OFF 同样领先。 DPA4 的优势并不局限于无机晶体。在分子领域的权威基准 SPICE-MACE-OFF 上,DPA4 以更低的参数量取得了新的 SOTA 成绩,力压此前的领先模型 eSEN,位列第一。从晶体材料到有机小分子、从能量到力的预测,DPA4 展现出跨体系、跨领域的一致优越性,进一步印证了其作为通用势能面模型的潜力。
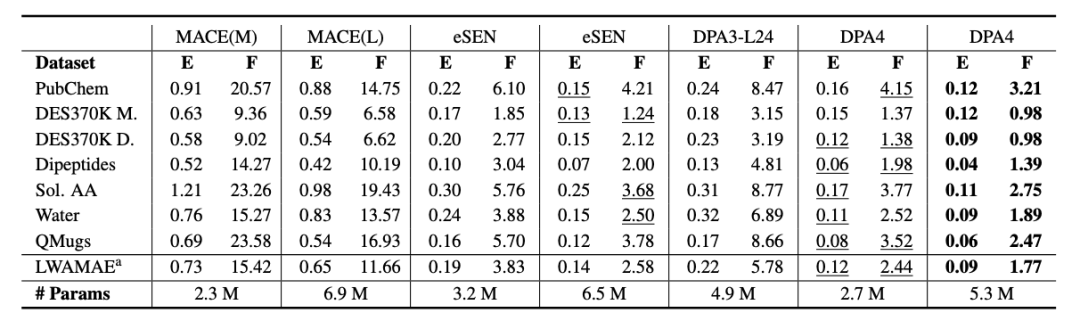
SPICE-MACE-OFF 表现
03 效率对比:重构“精度-效率”的帕累托前沿
如果说"双榜第一"证明了 DPA4 的精度,那么真正使其与众不同的,是它拿下这一精度的代价之低。
在以往,登顶榜单往往意味着更大的参数规模与更高的训练成本。DPA4 则在精度与训练成本这两个维度上同时刷新了帕累托前沿:
训练成本:理论上仅需 单张消费级 RTX 5090 显卡、训练约一天,即可达到此前榜单 SOTA 模型 eSEN 耗费 300 余 GPU days 才能实现的精度水平;
参数规模:在相同 CPS 下,DPA4 的参数量不足 eSEN 的十分之一;
代际提升:在相同精度下,DPA4 的训练效率较上一代 DPA3 进一步提升约 10 倍。
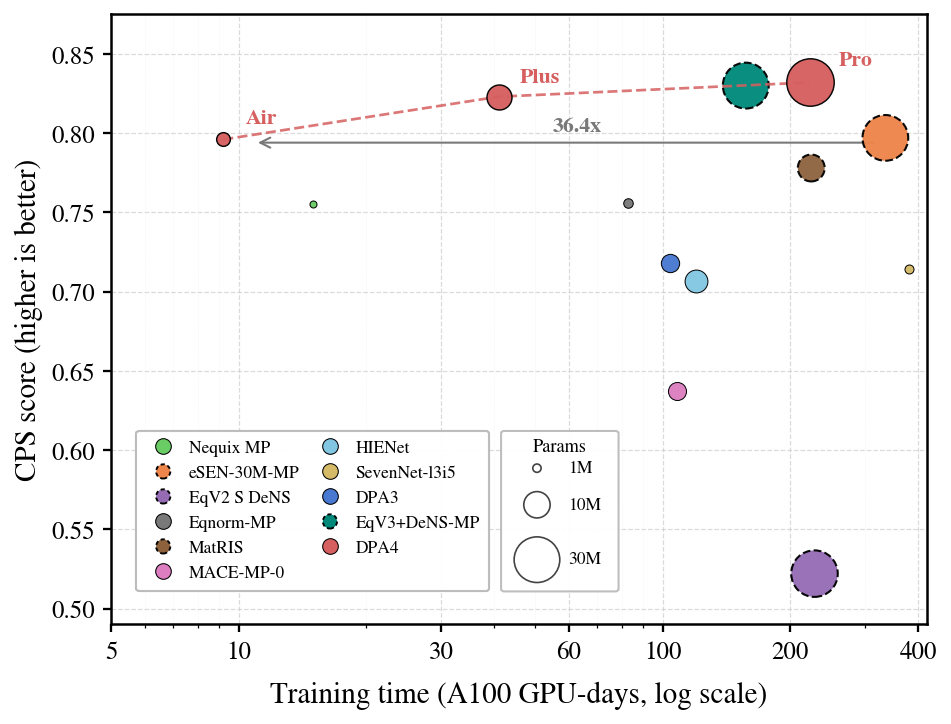
DPA4重构大原子模型“精度-效率”帕累托前沿
想要达到数量级的效率提升离不开工程上的优化,torch.compile 在普通的AI模型训练中是一个相对免费的提升,但是在机器学习势的训练中,力是能量的导数,因此势函数的训练离不开 double backward,而 compile 却不支持 double backward,因此长期以来,在机器学习势的训练中只能通过不断增大 batch size 来最大化 GPU 的利用率。DPA4 在世界范围内率先实现原生支持 torch.compile 编译的训练加速,并通过 autocast 到 bf16 精度实现显存的大幅降低,为单卡训练更大的模型提供了基础。

DPA4 开启 compile 以及 amp 的训练时间以及峰值显存占用对比
这一结果意味着,在同等算力预算下,研究者能够更快地完成训练与迭代、模拟更大尺度与更长时间跨度的微观过程。DPA4 把大规模、高通量的原子模拟,从"算力奢侈品"真正带入了"日常可用"的范畴,对电池材料、催化剂设计、半导体探索等领域具有重要的应用价值。
04 总 结
DPA4 是面向大原子模型(LAM)时代设计的新一代通用势函数架构。它通过局部坐标系下的 SO(2) 等变线性算子与注意力机制的协同设计,在严格满足物理对称性与能量守恒的前提下,大幅降低了等变计算的开销,并辅以原生 torch.compile 加速与原生 ZBL 支持,在工程层面进一步释放了性能。
在材料发现榜单 Matbench Discovery 与小分子基准 SPICE-MACE-OFF 上,DPA4 双双登顶世界第一,并在精度与训练成本上同时达到了全新的帕累托前沿——以不足十分之一的参数量、单卡一天的训练成本,匹敌乃至超越了昂贵的大模型。DPA4 有力地证明:高精度与高效率,从来不是一道单选题。
DPA4 的持续演进,离不开深势科技长期构建的“产学研”开放生态。围绕 Deep Modeling 开源社区,深势科技持续联动高校、科研院所、开发者与产业伙伴,将前沿算法研究、开源工具链建设、真实产业场景验证和社区协同创新连接起来,推动 AI for Science 从方法突破走向可复用、可扩展、可落地的基础设施。通过开源模型、开源软件、开放交流与开放协作,深势科技希望与全球研究者共同降低科学计算与创新的门槛,加速大原子模型时代的到来。
目前 DPA4 已面向 Deep Modeling 社区开放尝鲜,论文与正式版本将于后续陆续开源。在走向大原子模型时代的征途上,开源开放始终是我们坚持的主题,欢迎广大研究者持续关注,并加入交流、共同探索。
主要开发者及单位:
李天成(北京大学,北京科学智能研究院)
薛建明(北京大学)
张林峰(深势科技、北京科学智能研究院)
张铎(北京大学,北京科学智能研究院)
王涵(北京应用物理与计算数学研究所)

诚邀加入大原子模型计划,添加管理员微信,加入微信尝鲜群交流切磋
关于深势科技
深势科技是全球 AI for Science 开拓者和引领者,是国家高新技术企业、国家专精特新“小巨人”企业,在北京、上海、深圳等城市布局研发中心。依托在交叉学科领域的深耕,构建了“深势·宇知”AI for Science 大模型体系,并进一步解决科学研究和工业研发领域的关键问题,将众多学科的科研方法从“实验试错 / 计算机”时代带入了“预训练模型时代”,形成AI for Science 的“创新-落地”链路和开放生态,构建基于AI for Science的微尺度工业基础设施,赋能“千行百业”,为人类经济发展最基础的生物医药、能源、材料和信息科学与工程研究打造新一代研发系统。